CortexEngine¶
Overall process data transfer and query¶

- integration from an existing model (e.g. CSV file)
- storage in the CortexEngine and in the global dictionary
- simultaneous storage in the field dictionary
- query
- final reading of the results
CortexEngine field dictionary¶
Our field dictionary offers a structure that differs significantly from other systems. It not only enables faster queries, but also innovative approaches to data analysis and integration. The field dictionary is maintained completely and automatically by the Cortex-IP, so that no further adjustments are necessary.
The CortexEngine builds field dictionaries in several stages. Each content knows in which records and fields it is contained, while each field knows the various contents that can occur in it.
We offer a unique data management system that provides a universal structure for organizing information across any schema.
These field dictionaries reflect the entire data structure across all fields and their contents. All queries are handled in the field directory and the schematically stored data is only used for output. The small size enables very fast queries in any combination of queries. Every user can work immediately with the field dictionaries and does not need to make any adjustments, even if changes are made to the data model.
Field dictionary in the uniplex¶
Within the Uniplex, the list entry for each field can be displayed via the global dictionary. This shows the contents of the field used (across all record types) and the frequency (number) of contents in the data inventory. The ID list is therefore hidden behind each number.
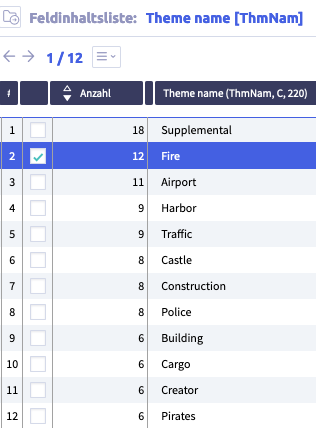
Each entry in this field dictionary can be viewed in a separate list, which enables direct access to records with the corresponding content.
The queries within the data inventory are performed by combining different field dictionaries. Using intersection, difference set, symmetrical difference set and union set, only the occurrences are combined with each other and the records are only read when they are output.
Note for developers and administrators
The field dictionary of a field contains a list of record IDs. Each of these IDs is managed internally with 12 bytes. For example, if a content with the number 1 appears in the list, the list has a length of 12 bytes. If the number is 10, the list is 120 bytes long, and so on. The memory requirement of a list entry therefore depends on the number of different contents per field and the number of different fields.
Memory requirement for selections
When combining several list entries to find content via the intersection set, union set, difference set or symmetrical difference set, the ID lists (therefore n12 bytes) are combined with each other. This requires the appropriate amount of working memory to be available.
Queries¶
Queries can be made using simple quantity combinations because the CortexEngine manages each content and each field in a field dictionary.
Smith: ID1; ID2; ID3; ID5; ID8; ID13
New York: ID2; ID4; ID6; ID8; ID10
Intersection = [Smith] and [New York] = ID2; ID8
The intersection of the IDs of the fields Name for Smith and City for New York results in a new ID list with two contents. Only after this combination has been carried out will the contents of affected records be displayed or further processed. Before this point, it is not necessary to read the records, but only to read the ID lists (i.e. the list entry).
Multi model¶
CortexEngine offers the possibility of using various functions in its schemaless storage structure. For example, structures can be created using link fields. In addition, individual fields can be used as often as required in a data inventory, for example for bank details or e-mail addresses. It is also possible to save past, current and future values for each field in a data inventory. This type of storage is known as bitemporal data storage.
Internally, the data structure is stored similar to the 6th normal form based on key-value stores. In this case, we are talking about a multidimensional key-value store. The example shows the record of a person with the link to another person and its description over time.
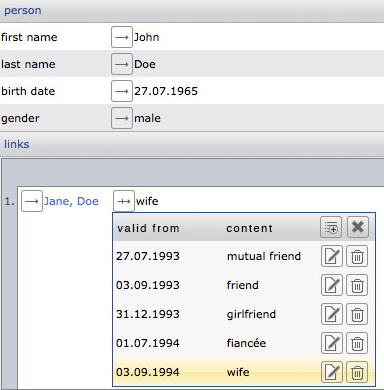
Each of these options can also be combined with the others (e.g. for the temporal change of several links.
Bitemporal¶
The CortexEngine saves the transaction time of changes to a record. In addition, each content of all fields within a record can be assigned a time from which the information is considered correct and up-to-date. This not only shows the status of a record, but also the history of the last transaction.
The transaction time is automatically maintained by the server, while the validity of a value is determined by the user or by automated processes such as data import or interfaces. If no validity has been defined, the value remains unknown until it is overwritten by a new value (another transaction overwrites this value) or another value with a time reference is inserted).
Example¶
Information about transactions can be displayed within a record.
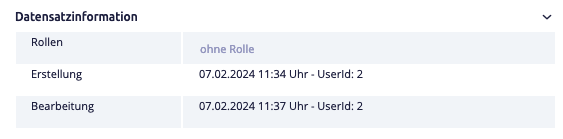
In contrast, the history information (or processing history) shows the validity of a value in a field. This can be displayed and explicitly maintained for each field. If the validity of a value is unknown, the value is permanently valid until it is overwritten by a new value. The standard view of a record only ever shows the currently valid value.

IDs in the CortexEngine¶
An ID in the CortexEngine is a unique identifier that is assigned to each record. The engine generates these IDs by combining the timestamp, the internal counter, the user ID and the location ID. This ensures that each ID is unique and is only assigned once.
Memory requirement¶
In order to use the right hardware, an estimate of the expected memory requirements is often required before a new data storage system is used. In addition to memory, other resources are also relevant to ensure runtime. The framework parameters for hard disks (HDD or SSD), processors (CPU) and main memory (RAM) must therefore be defined as a whole.
Use of hard disks (HDD or SSD)
It is recommended to use SSD. For more detailed information on storage requirements and the layout of the landscape, please contact our customer support (cortex-info@cortex-ag.com).
Here, the memory requirement depends considerably on several parameters that can only be read in part or not at all from the existing data inventories. Examples of these include
- number of records
- length of the field contents
- length of the field synonyms used
- number of different contents per field
- number and size of binary data
- number of fields per record type
- frequency of repetition fields per data inventory
Note
Please note that the memory requirements are not comparable with other systems because the CortexEngine transfers all content to the global dictionary via containers and thus ensures that any query is universally available.