CortexEngine¶
Gesamtprozess Datenübertragung und Abfrage¶
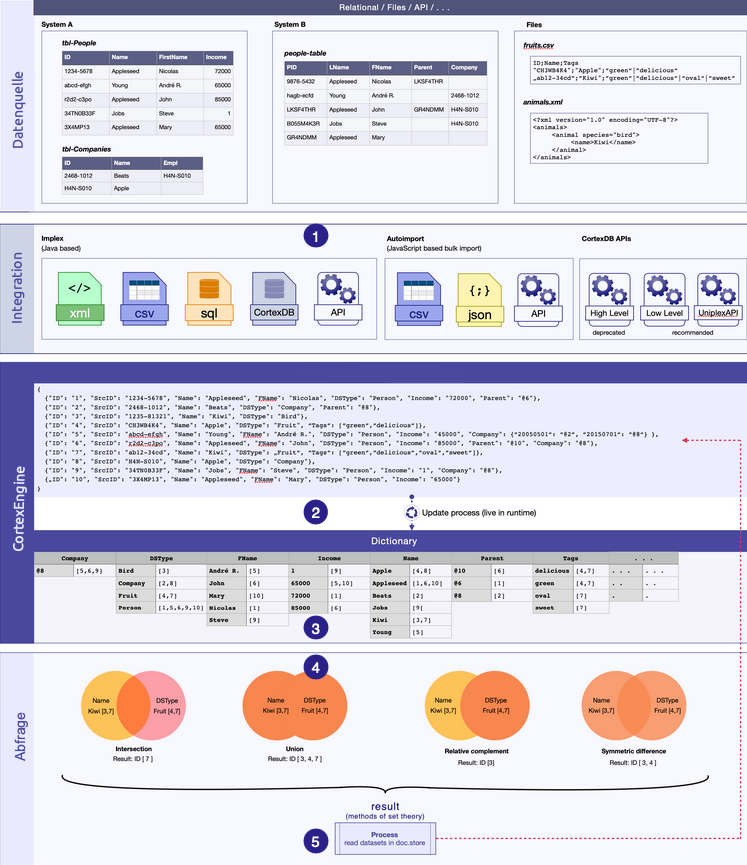
- Integration aus einem vorhandenen Modell (z.B. CSV-Datei)
- Speicherung in der CortexEngine und im Stichwortverzeichnis
- gleichzeitige Speicherung in der Feldinhaltsliste
- Abfrage
- endgültiges Lesen der Ergebnisse
CortexEngine-Feldinhaltsliste¶
Unsere Feldinhaltsliste bietet Ihnen eine Struktur, die sich deutlich von anderen Systemen unterscheidet. Es ermöglicht nicht nur schnellere Abfragen, sondern auch innovative Lösungsansätze für Datenanalyse und -integration. Die Pflege der Feldinhaltsliste wird vollständig und automatisch von der Cortex-IP übernommen, sodass keine weiteren Anpassungen nötig sind.
Die CortexEngine baut Feldinhaltslisten mehrstufig auf. Dabei ist jedem Inhalt bekannt, in welchen Datensätzen und Feldern er enthalten ist, während jedes Feld die verschiedenen Inhalte kennt, die darin vorkommen können.
Damit bieten wir eine einzigartige Datenhaltung, die eine universelle Struktur über alle enthaltenen Informationen in einem beliebigen Schema ermöglicht.
Diese Feldinhaltslisten spiegeln dabei über alle Felder und deren Inhalte hinweg die gesamte Datenstruktur ab. Alle Abfragen werden im Feldverzeichnis behandelt und die schemalos gespeicherten Daten werden nur zur Ausgabe verwendet. Die geringe Größe ermöglicht sehr schnelle Abfragen in beliebigen Abfragekombinationen. Jeder Nutzer kann sofort mit der oder den Feldinhaltslisten arbeiten und braucht daher, auch bei Änderungen am Datenmodell, keinerlei Anpassungen vorzunehmen.
Feldinhaltsliste im Uniplex¶
Innerhalb des Uniplex kann über das Stichwortverzeichnis der Listeneintrag zu jedem Feld angezeigt werden. Dieser zeigt die verwendeten Inhalte des Feldes (über alle Datensatztypen) und die Häufigkeit (Anzahl) der Inhalte im Datenbestand. Hinter jeder Anzahl verbirgt sich daher die ID-Liste.
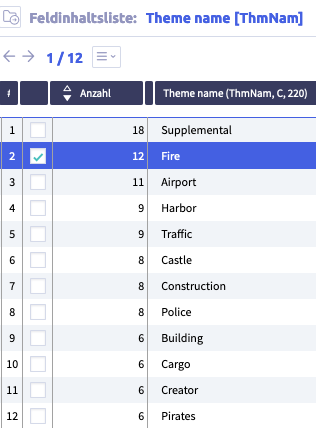
Jeder Eintrag in dieser Feldinhaltsliste kann in einer separaten Liste betrachtet werden, was einen direkten Zugriff auf Datensätze mit den entsprechenden Inhalten ermöglicht.
Durch eine Mengenkombination verschiedener Feldinhaltslisten erfolgen so die Abfragen innerhalb des Datenbestands. Über Schnittmenge, Differenzmenge, symmetrische Differenzmenge und Vereinigungsmenge werden nur die Vorkommen miteinander kombiniert und erst bei der Ausgabe erfolgt das Lesen der Datensätze.
Hinweis für Entwickler und Administratoren
Die Feldinhaltsliste eines Feldes enthält eine Auflistung von Datensatz-IDs. Jede dieser IDs wird intern mit 12 Byte verwaltet. Wenn beispielsweise ein Inhalt mit der Anzahl 1 in der Liste erscheint, hat die Liste eine Länge von 12 Byte. Bei einer Anzahl von 10 beträgt die Liste entsprechend 120 Byte, und so weiter. Der Speicherbedarf eines Listeneintrags hängt daher von der Anzahl der verschiedenen Inhalte pro Feld sowie der Anzahl der verschiedenen Felder ab.
Speicherbedarf bei Selektionen
Bei einer Kombination mehrerer Listeneinträge zum Auffinden von Inhalten über die Schnittmenge, Vereinigungsmenge, Differenzmenge oder symmetrische Differenzmenge werden die ID-Listen (also n12 Byte) miteinander kombiniert. Hierfür muss die entsprechende Menge an Arbeitsspeicher zur Verfügung stehen.
Abfragen¶
Dadurch, dass die CortexEngine jeden Inhalt und jedes Feld in einer Feldinhaltsliste führt, erfolgen Abfragen über einfache Mengenkombinationen.
Meyer: ID1; ID2; ID3; ID5; ID8; ID13
Hamburg: ID2; ID4; ID6; ID8; ID10
Schnittmenge = [Meyer] und [Hamburg] = ID2; ID8
Die Schnittmenge aus den IDs der Felder Name für Meyer und Ort für Hamburg ergibt eine neue ID-Liste mit zwei Inhalten. Erst nachdem diese Kombination durchgeführt wurde, erfolgt die Anzeige oder Weiterverarbeitung der Inhalte betroffener Datensätze. Vor diesem Zeitpunkt ist kein Lesen der Datensätze notwendig, sondern nur das Lesen der ID-Listen (also des Listeneintrags).
Multi Model¶
In ihrer schemalosen Ablagestruktur bietet die CortexEngine die Möglichkeit, verschiedene Funktionen zu nutzen. Beispielsweise können Strukturen über Verweisfelder erstellt werden. Zusätzlich können einzelne Felder beliebig oft in einem Datenbestand genutzt werden, unter anderem für Bankverbindungen oder E-Mail-Adressen. Es ist auch möglich, vergangene, aktuelle und zukünftige Werte für jedes Feld eines Datenbestands zu speichern. Diese Art der Speicherung wird als bitemporale Datenhaltung bezeichnet.
Intern wird die Datenstruktur ähnlich der 6. Normalform in Anlehnung an Key-Value-Stores gespeichert, wir sprechen hier von einem mehrdimensionalen Key-Value Store. Das Beispiel zeigt den Datensatz einer Person mit dem Verweis auf eine andere Person und dessen Beschreibung im zeitlichen Verlauf.
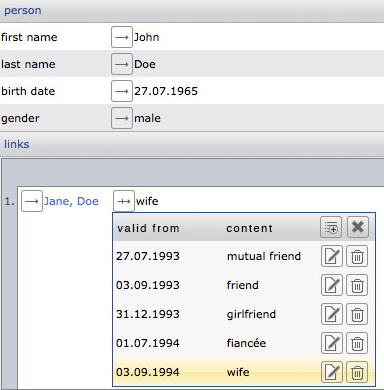
Jede dieser Möglichkeiten kann mit den anderen auch kombiniert werden (z.B. für die zeitliche Veränderung von mehreren Verweisen).
Bitemporal¶
Die CortexEngine speichert die Transaktionszeit der Änderungen an einem Datensatz. Darüber hinaus kann jedem Inhalt aller Felder innerhalb eines Datensatzes ein Zeitpunkt zugewiesen werden, ab dem die Information als korrekt und aktuell gilt. Dadurch ist nicht nur der Zustand eines Datensatzes, sondern auch die Historie bei der letzten Transaktion ersichtlich.
Die Transaktionszeit wird automatisch vom Server gepflegt, während die Gültigkeit eines Wertes vom Anwender oder von Automatismen wie dem Datenimport oder Schnittstellen festgelegt wird. Wenn keine Gültigkeit festgelegt wurde, bleibt der Wert als unbekannt erhalten, bis er durch einen neuen Wert überschrieben wird (eine weitere Transaktion überschreibt diesen Wert) oder ein weiterer Wert mit einem zeitlichen Bezug eingefügt wird.
Beispiel¶
Informationen über Transaktionen können innerhalb eines Datensatzes angezeigt werden.
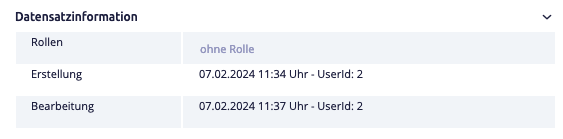
Im Gegensatz dazu zeigen die Verlaufsinformationen (oder auch Verlaufsbearbeitung) die Gültigkeit eines Wertes in einem Feld. Diese können zu jedem Feld eingeblendet und explizit gepflegt werden. Ist für einen Wert die Gültigkeit unbekannt, gilt der Wert dauerhaft so lange, bis dieser von einem neuen Wert überschrieben wird. Die Standardansicht eines Datensatzes zeigt dabei immer nur den aktuell gültigen Wert an.

IDs in der CortexEngine¶
Eine ID in der CortexEngine ist ein eindeutiger Identifikator, der jedem Datensatz zugewiesen wird. Die Engine generiert diese IDs, indem sie den Zeitstempel, den internen Zähler, die Benutzer-ID und die Standort-ID miteinander kombiniert. Dadurch wird sichergestellt, dass jede ID einmalig ist und nur einmal vergeben wird.
Speicherbedarf¶
Um die richtige Hardware einzusetzen, wird vor dem Einsatz eines neuen Datenhaltungssystems häufig eine Einschätzung des zu erwartenden Speicherbedarfs gefordert. Neben dem Speicher sind zudem auch andere Ressourcen relevant, um die Laufzeit sicherzustellen. Die Rahmenparameter für Festplatten (HDD oder SSD), Prozessoren (CPU) und Arbeitsspeicher (RAM) sind daher insgesamt festzulegen.
Nutzung von Festplatten (HDD oder SSD)
Es wird empfohlen, SSD zu nutzen. Für genauere Informationen, wie der Speicherbedarf und die Auslegung der Landschaft erfolgen kann, wenden Sie sich bitte an unseren Kundensupport (cortex-info@cortex-ag.com).
Hierbei hängt der Speicherbedarf erheblich von mehreren Parametern ab, die nur teilweise oder überhaupt nicht aus den vorhandenen Datenbeständen abgelesen werden können. Beispielhaft zählen dazu unter anderem:
- Anzahl der Datensätze
- Länge der Feldinhalte
- Länge der verwendeten Feldsynonyme
- Anzahl unterschiedlicher Inhalte je Feld
- Anzahl und Größe von Binärdaten
- Anzahl der Felder je Datensatztyp
- Häufigkeit von Wiederholfeldern je Datenbestand
Hinweis
Bitte beachten Sie, dass der Speicherbedarf nicht mit anderen Systemen vergleichbar ist, weil die CortexEngine alle Inhalte über Container in das Stichwortverzeichnis überführt und somit jede beliebige Abfrage universell sicherstellt.